

When we first introduced personalization at Prepr, we did it with conviction. We believed that adaptive content and experiments could help teams build better digital experiences, experiences that respond to real people, not assumptions. And over time, that belief proved right. Teams started personalizing homepages, testing hero messages, and tailoring content to different audiences.
But from the very beginning, we also knew one important piece was missing.
With the release of Impact Goals for personalization and A/B testing, that missing piece is now in place. Impact Goals make it possible to measure what experiments actually achieve, directly inside Prepr. They complete a vision we started working toward years ago: not just running experiments, but clearly understanding their effect on meaningful outcomes.
Why CTR alone was never enough
For a long time, optimization in digital teams revolved around what was easiest to measure. Clicks. Views. Click-through rate. These metrics were visible, immediate, and simple to compare across variants. When you launched an A/B test on a homepage banner or personalized a hero message, CTR was usually the first signal you looked at.
And CTR does matter. It tells you whether something catches attention. It shows whether a message resonates enough for someone to interact. But in practice, a higher click-through rate did not always translate into better outcomes.
A variant could win on clicks and still fail to move users closer to a real goal. Visitors might click a button but never continue their journey. They might engage with a personalized message and still leave without signing up, requesting a quote, or returning later. In other words, surface-level engagement was easy to measure, but it didn’t explain what happened next.
To understand that deeper impact, marketers had to rely on external analytics tools. Data had to be sent to platforms like Google Analytics, goals had to be recreated there, and results had to be matched back to experiments manually. This made experimentation slower, more complex, and harder to trust.
Over time, this created a clear split. Experiments were running inside Prepr, but the real answers lived somewhere else. As long as that gap existed, optimization was always based on partial insight.
Micro vs macro conversions: why the difference matters
To understand why Impact Goals change how experimentation works in Prepr, it helps to be clear about the difference between micro and macro conversions.
Micro conversions are the small, immediate actions people take on a website. Clicking a button. Opening a menu. Tapping a link. These actions are easy to measure and happen close to the moment someone sees a piece of content. For years, they have been the default way to evaluate experiments. If variant B gets more clicks than variant A, it feels like progress.
Macro conversions are different. They represent outcomes that actually matter to the business. Requesting a quote. Signing up for an account. Completing a purchase. Returning multiple times within a short period. These actions usually don’t happen instantly, and they often depend on more than a single interaction.

The problem is that micro conversions and macro conversions don’t always move in the same direction.
A personalized hero message might generate more clicks, but those visitors may never continue their journey. An A/B test could win on CTR while quietly reducing the number of people who reach a signup or checkout. When teams optimize only for micro conversions, they risk improving what’s visible while missing what’s important.
That doesn’t mean micro conversions are useless. They are still valuable signals. A click can show interest. It can indicate that a message is clear or compelling. But on their own, they don’t explain whether an experiment actually helped users move forward.
With Goals, micro and macro conversions can finally live together in the same experiment. A micro conversion, such as clicking a “Find a car” button, can be tracked as a secondary signal. A macro conversion, such as requesting a quote within a day, can be tracked as the primary outcome. Both are measured in context, tied directly to the same piece of personalized content or A/B test.
Introducing Impact Goals for experiments
An Impact Goal in Prepr defines what success looks like for an experiment. Instead of measuring a single interaction, it lets teams measure higher-level conversions and engagement outcomes that matter to the business. For example, a goal can describe visitors who view a specific page and then click a call to action, or users who complete a custom event such as requesting a quote or making a purchase.
These goals are built on real customer behavior and simple logic, which makes it possible to measure intent rather than isolated clicks. Once a goal is defined, it can be linked directly to personalization or A/B testing experiments. Prepr then tracks how many visitors who saw each variant actually reached that outcome.
This is what makes Impact Goals valuable. They show the overall impact of personalization and A/B testing on conversions, not just on element-level interactions. Teams can still track micro-conversions like button clicks, but they can also measure macro-conversions that reflect real business results.
How Impact Goals for experiments work in Prepr
Impact Goals in Prepr are designed to fit naturally into the way teams already work with personalization and A/B testing. Everything happens inside the same product where experiments are created and managed.
Goals live in the Segments section, where you’ll find a dedicated area to create them. A goal is built from one or more behavioral conditions based on visitor events. These events describe how visitors interact with your site: viewing content, clicking elements, subscribing, or triggering custom events that you track on your website, such as “Request a quote” or “Complete purchase.”

Selecting a click event and setting conditions for the “Request a quote” goal.
When defining a goal, most teams start simple. In many cases, a single condition is enough, for example, tracking how many visitors complete a sign-up or trigger a request form after seeing an experiment. This already allows teams to measure conversions beyond clicks and understand how personalization or A/B testing contributes to real outcomes.
For more advanced use cases, goals can also capture broader behavior. A goal might describe visitors who view a specific page multiple times and then click a call to action, or who complete a custom event. These conditions can be combined using simple logic, such as AND or OR, so the goal reflects how users actually move through the site.
You can also narrow things down further. Impact Goals let you specify:
- which events matter ( a specific page view or a custom event),
- how often an event needs to happen,
- and within what time frame that behavior should occur.
This flexibility makes it possible to define both simple engagement goals and more advanced, high-value outcomes without turning goal setup into a technical exercise.
Once a goal is defined, it becomes available inside your content. When you open a content item that contains adaptive content or an A/B test, you can link goals directly to that experiment. Typically, teams set one primary goal for a macro conversion, such as submitting a form or completing a key action, and one or more secondary goals for supporting signals like clicks or early engagement.

Selecting a primary and secondary goal for an adaptive content experiment.
From that moment on, Prepr starts tracking how visitors who see each variant perform against those goals. The platform measures how many people reach the goal within a defined time window after seeing the personalized content or test variant. There is no manual matching of data and no guessing which variant contributed to which outcome.
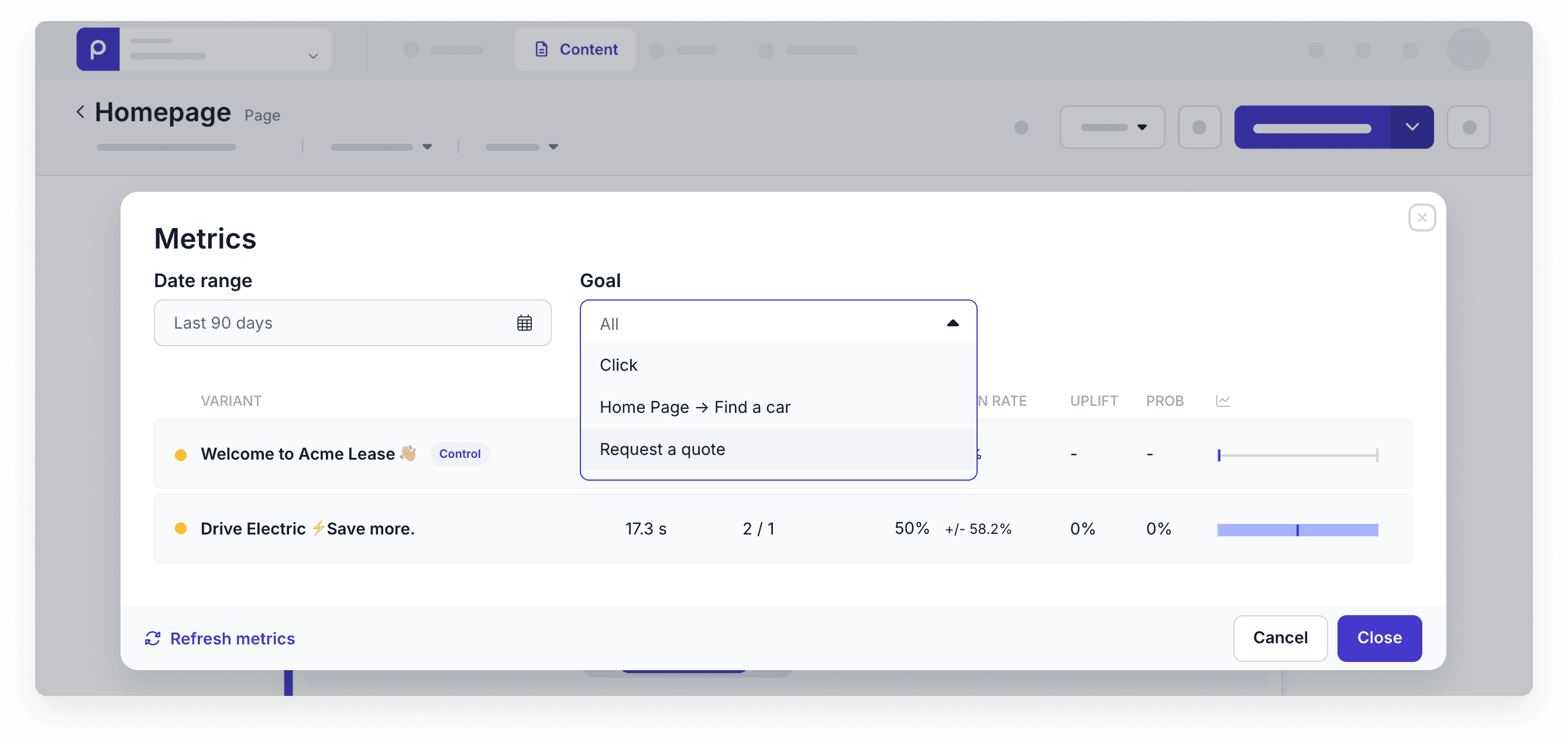
Viewing experiment results filtered by the selected goal.
The result is a clear line between experimentation and impact. You can see, inside the same experiment, not just which variant gets more attention, but which one actually moves people forward in the journey.
The full configuration options are documented in detail in Prepr’s product documentation, where teams can explore more advanced goal setups as their experimentation matures.
More than a release: A step toward an intelligent website
This release is not just about adding another feature to Prepr. It marks the moment when an idea we’ve been working toward for years becomes real.
From the start, personalization in Prepr was never only about showing different content to different audiences. The goal was always to help teams understand how their websites behave, how people move through them, and how content decisions influence real outcomes. For a long time, one part of that vision remained incomplete. We could personalize and experiment, and we could see engagement signals, but connecting those experiments to results that truly matter to a business was still difficult.
Goals change that. By linking personalization and A/B testing directly to meaningful outcomes, experiments stop being isolated exercises and become part of a learning system. Teams can see what happens after a personalized message is shown, after a click, or even when there is no click, and whether an experiment actually helps users move forward.
This is an important step toward what we mean by an intelligent website: one that doesn’t just react, but learns over time. It also changes how teams work together. Marketers, product managers, and developers can align around shared definitions of success, using the same data in the same place. Decisions become clearer, faster, and easier to trust.
Goals are not the end of the roadmap. They are a foundation, one that turns experimentation into learning and brings us closer to websites that understand their users and improve because of it.


